Architecture and Deployment
The LittleHorse Kernel, which can be found on our GitHub, is an enterprise-ready workflow engine that can scale to the largest workloads while meeting the most strict security requirements when deployed on premise. The LittleHorse Kernel is licensed under the Open Software Initiave-certified AGPL-v3 license.
This section is intended to give the community the information that they need in order to successfully run LittleHorse in production. In addition to reading the docs, we recommend that you join our Slack Community and ask questions there! You can also raise issues on our GitHub.
If you would like support or professional services for LittleHorse OSS, contact the LittleHorse Enterprises LLC team at sales@littlehorse.io or visit our website. Alternatively, LittleHorse Enterprises provides a managed on-premise service (LittleHorse Platform) and a fully-managed cloud service (LittleHorse Cloud) for LittleHorse.
For free commmunity support, join us on Slack and ask us a question! The contributors (both inside and outside of LittleHorse Enterprises LLC) are very active and helpful on Slack.
Introduction
For performance reasons, LittleHorse does not rely upon an external database. Instead, we built our own data store using Kafka as a write-ahead-log and using RocksDB/Speedb as our indexing layer. Kafka is a distributed log that supports partitioning, replication, and transactions, making it ideal as the backbone for the LittleHorse data store.
As such, LittleHorse has a dependency on Kafka. We have optional integrations with Prometheus, Grafana, any TLS system (such as openssl or Cert Manager), and any OAuth Identity Provider (eg. Keycloak or Auth0).
The LittleHorse Kernel's dependencies are:
- Apache Kafka
- Optional: An Oauth Provider for client authentication
- Optional: A TLS certificate manager
- Optional: A Prometheus-compatible system for monitoring
Deployment Options
The LittleHorse Kernel is available for deployment in three ways:
- Self-managed via LittleHorse OSS, free of charge in your own environment.
- Supported by LittleHorse for Kubernetes in your own environment, and managed on autopilot by our Kubernetes Operator.
- As a hosted SaaS service in LittleHorse Cloud.
- LittleHorse OSS
- LittleHorse for Kubernetes
- LittleHorse Cloud
As the LittleHorse Kernel is source-available under the AGPL-v3 license, you can run LittleHorse free of charge in production on your own infrastructure. You can get the code from our GitHub Repo, and our repo has quickstart tutorials for running LittleHorse using our public docker image.
LittleHorse for Kubernetes (LHK) is an enterprise-ready managed installation of LittleHorse in your Kubernetes cluster. It is delivered through a subscription to a Kubernetes Operator, which takes LittleHorse from a stick-shift car (LittleHorse OSS) and turns it into a Tesla.
LHK is suitable for large enterprises who have strict data privacy and security requirements, and who are uncomfortable with allowing data to leave their four walls. LittleHorse Platform is highly configurable, yet it is also simple and comes with sensible defaults, 24/7 support, and hands-off upgrades.
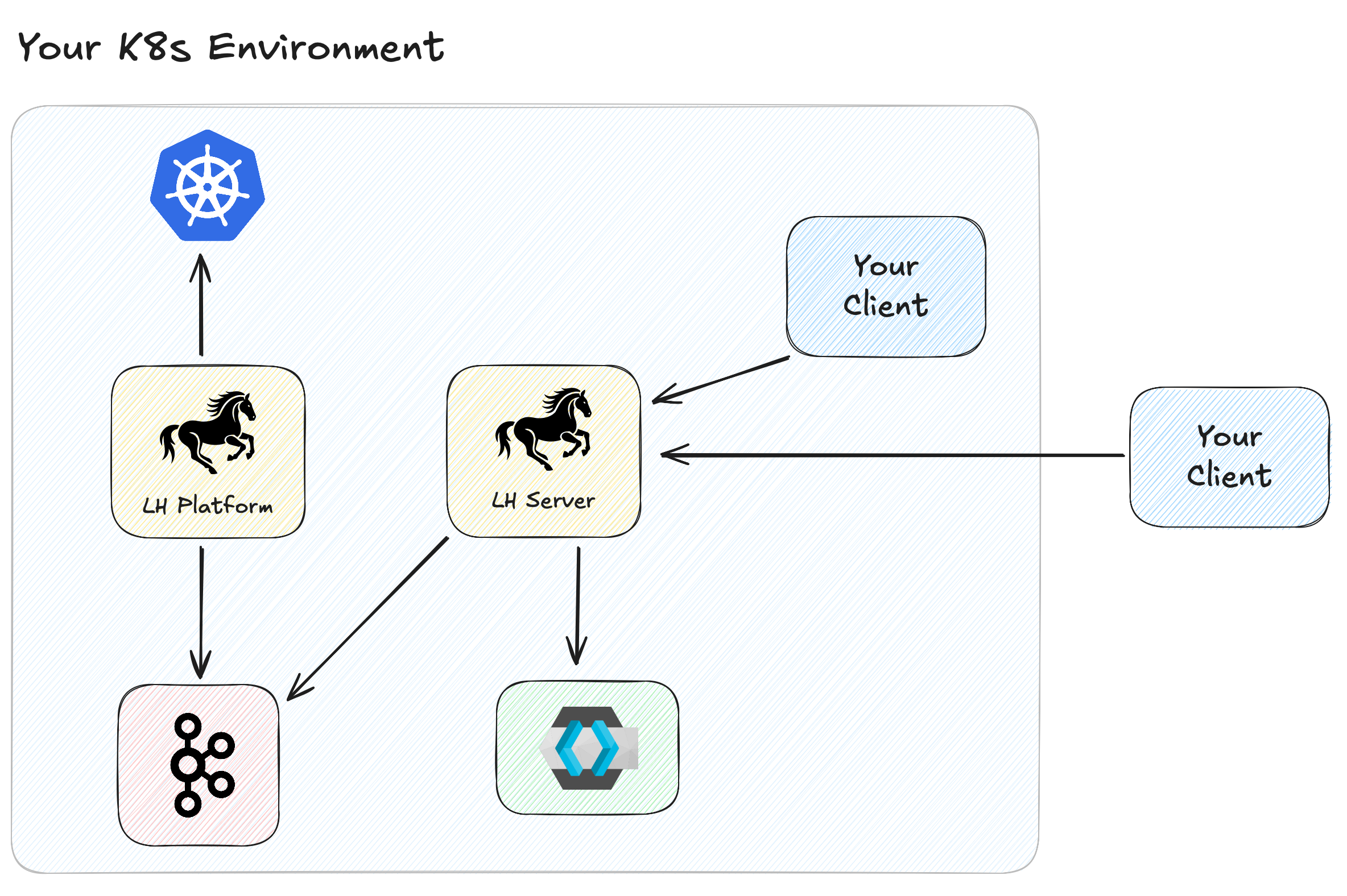
To inquire about LittleHorse for Kubernetes, fill out the waitlist form or contact sales@littlehorse.io.
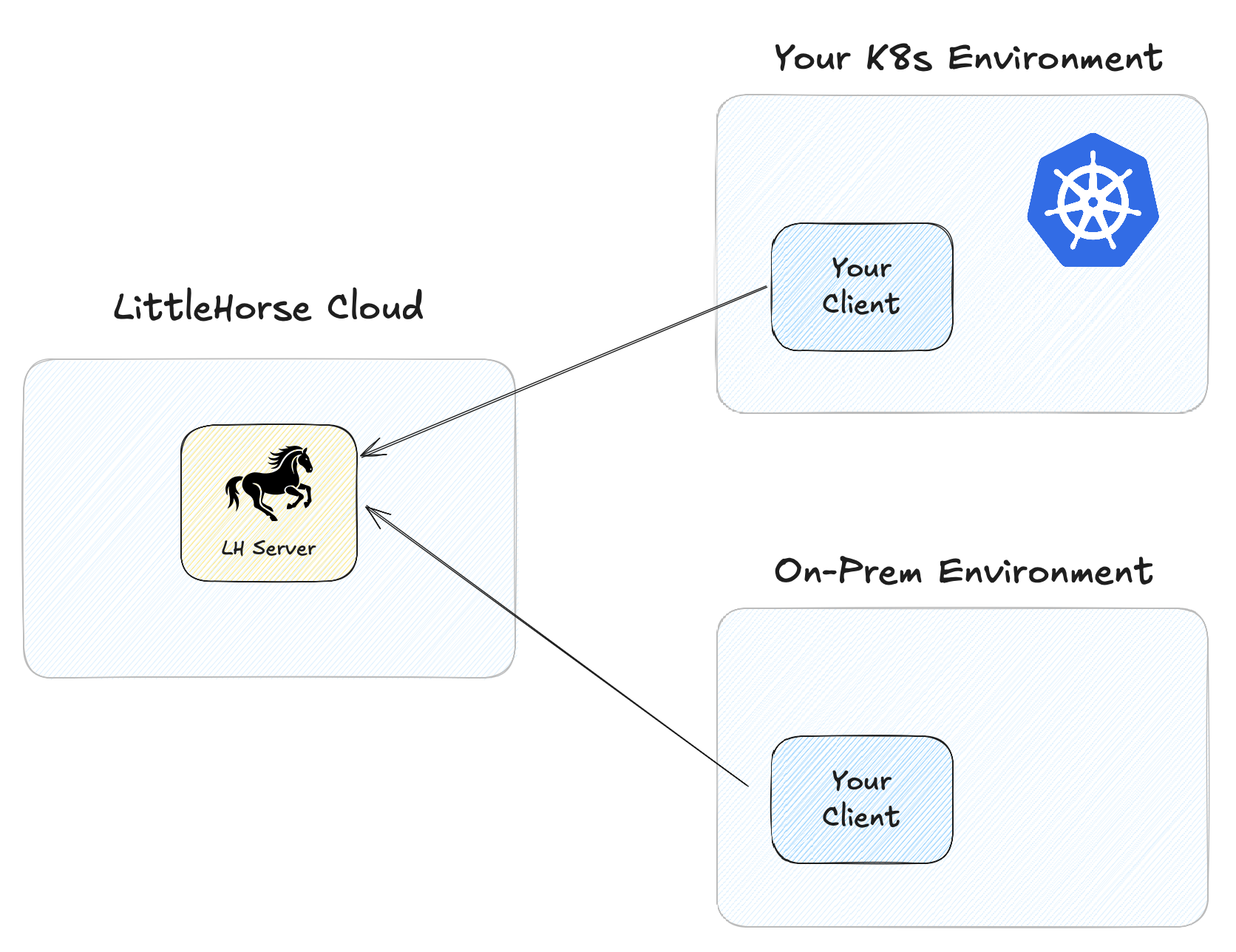
In LittleHorse Cloud, all of the operational burden of running LittleHorse is handled for you. A team of experts runs LittleHorse securely in our cloud environment, allowing you to focus on your business processes. We will support several flavors of LittleHorse Cloud:
- Standard: serverless, pay-as-you-go offereing.
- Reserved: save money by reserving capacity up-front.
- Dedicated: maximum-security, dedicated installation with VPC peering into your own account.
Security
The LittleHorse Kernel supports various security mechanisms:
- TLS to encrypt incoming connections.
- Federated identity for authentication (either mTLS or OAuth).
- mTLS to secure inter-server communication.
LittleHorse for Kubernetes has integrations with the Gateway API, Cert Manager, and Keycloak. Additionally, since LittleHorse Platform runs entirely in your own network, your firewall rules can add an additional layer of security.
LittleHorse Cloud uses TLS and OAuth for client authentication, and SSO for access to the LittleHorse Dashboard.
LittleHorse Kernel Components
The LittleHorse Kernel internally is a stateful Kafka Streams application, and it exposes a public GRPC API. Note that Kafka is just an implementation detail of LittleHorse and is not exposed to the LittleHorse clients.
The LittleHorse Kernel is itself just a Java application that stores information locally on disk and talks to a Kafka cluster. Therefore, all you really need to run LittleHorse is is a disk, a Kafka Cluster, and a JVM.
Advertised Listeners
For most uses of the GRPC API, the client can connect to any LittleHorse Kernel in the cluster, and the contacted server will transparently route the request to the appropriate other LittleHorse Kernel Instance(s), and return the final result back to the client. For this use-case, the clients do not need the ability to connect to a specific LittleHorse Kernel Instance.
However, the Task Workers need to be able to address individual servers directly. This is because, to avoid costly distributed coordination, a scheduled TaskRun is only managed and maintained by a single LittleHorse Kernel, and the internal Task Queue's are partitioned by the server. Therefore, in order to ensure that all TaskRun's are completed, the Task Workers for a certain TaskDef collectively need to connect to all of the LittleHorse Kernel Instances.
In order to reduce wasteful network connections, the LittleHorse Kernel has a Task Worker Assignment Protocol which, upon every Task Worker Heartbeat, assigns a list of LittleHorse Kernel Instances for each Task Worker to connect to.
As a consequence, every LittleHorse Kernel needs to have an "advertised" host and port for each configured internal listener, so that the Task Workers can "discover" where to connect to.
This all sounds really complicated, but don't worry! It happens transparently under the hood in our Task Worker SDK. You won't have to worry about balancing Task Workers; all you need to do is configure advertised listeners! This is similar to Kafka Consumer Groups.
Internal Listeners
LittleHorse is a partitioned system, meaning that not all data lives on all of the nodes. Therefore, when a request arrives on Server Instance 1, instance 1 may have to ask Instance 2 for the answer! LittleHorse has a special port for LittleHorse Kernel Instances to communicate with each other.
Kafka Streams
LittleHorse is built on Kafka Streams because, quite simply, there was no other way to reach the performance numbers we wanted with any other backing data store (note: benchmarks are coming soon!).
It's safe to say that Kafka Streams is an incredibly powerful and beautiful piece of technology. However, with great power comes great complexity, so it's advisable that you understand Streams at a basic level before running the LittleHorse Kernel in production.
For some primers on Kafka Streams operations, our friends at Responsive have posted some fantastic Blog Posts that you should check out. These blogs are general to Kafka Streams, not LittleHorse, but we have considered those topics when running LittleHorse in production for LittleHorse Cloud.
If you are concerned about the complexity of running LittleHorse in production, don't worry! You can also use our Cloud Service, or get expert support from LittleHorse Enterprises when running on-premise.
Apache Kafka Requirements
Properly configuring Kafka is necessary for a production-ready LittleHorse installation. In this section, we discuss what LittleHorse requires of Kafka.
Topics
LittleHorse is internally a Kafka Streams application with four sub-topologies. These topologies require having proper Kafka Topics configured. The required topics are:
- Core Command Topic
"{LHS_CLUSTER_ID}-core-cmd"- Partition Count:
LHS_CLUSTER_PARTITIONS
- Core Changelog Topic
"{LHS_CLUSTER_ID}-core-store-changelog"- Partition Count:
LHS_CLUSTER_PARTITIONS
- Repartition Command Topic
"{LHS_CLUSTER_ID}-core-repartition"- Partition Count:
LHS_CLUSTER_PARTITIONS
- Repartition Changelog Topic
"{LHS_CLUSTER_ID}-core-repartition-store-changelog"- Partition Count:
LHS_CLUSTER_PARTITIONS
- Metadata Command Topic
"{LHS_CLUSTER_ID}-global-metadata-cl"- Partition Count: 1
- Metadata Changelog Topic
"{LHS_CLUSTER_ID}-global-metadata-cl"- Partition Count: 1
- Timer Command Topic
"{LHS_CLUSTER_ID}-timers"- Partition Count:
LHS_CLUSTER_PARTITIONS
- Timer Changelog Topic
"{LHS_CLUSTER_ID}-timer-changelog"- Partition Count:
LHS_CLUSTER_PARTITIONS
Security
We recommend that you create a Kafka Principal for the LittleHorse Kernel. It requires the following permissions:
- Topics:
DESCRIBEDESCRIBECONFIGSIDEMPOTENTWRITEWRITEREADCLUSTERACTION
- Groups:
ALL
- Transaction ID:
ALL
For security, all rules should be scoped to only entities with a prefix matching the LHS_CLUSTER_ID.
Workload
It should be noted that the LittleHorse workload heavily uses Kafka Transactions and compacted topics. In particular, the transaction-heavy nature of the workload means that, relative to other Kafka workloads, the brokers used by LittleHorse will require a higher ratio of CPU to Network Bandwidth.
As with all Kafka deployments, it is strongly recommended to provision significant memory for your Kafka brokers so that tail-reading consumers (i.e. the LittleHorse Kernel) can read data fresh off the Kafka Broker's page cache rather than reading from disk. This has a significant effect on the latency of the LittleHorse Kernel.
LittleHorse Internals
LittleHorse is a distributed system that we engineered to handle the most demanding workloads. That means that we have:
- Partitioning, to distribute work across multiple servers for horizontal scalability.
- Replication, to ensure high availability and durability in case a server instance crashes.
For an in-depth deep dive on the architecture of Kafka Streams and the LittleHorse Kernel, we recommend you take a look at Colt's talk at Confluent's Current 2024 conference.
Data Storage
The LittleHorse Kernel processes all data and serves all queries from RocksDB. RocksDB stores data in SST files on disk. The LittleHorse Kernel uses disk to persist the data stored on RocksDB between server restarts (i.e. during a rolling upgrade or after a crash recovery). If a LittleHorse Kernel instance starts up and data is missing, then the data on RocksDB is re-constructed by replaying Kafka changelog topics. This process is time-consuming but it does ensure reliability so long as your Kafka cluster is durable. However, this process can largely be avoided by providing persistent storage to the LittleHorse Kernel.
The most important takeaway from this section is that the LittleHorse Kernel is stateful, so you should provision sufficient storage to handle your workloads, and also ensure that you monitor free disk space.
Request Handling
LittleHorse built its own data store RocksDB as the indexing layer and Kafka as a WAL (all through Kafka Streams). The request processing flow has two phases:
- The request is recorded to a Kafka topic.
- A Kafka Streams Processor on one of the LittleHorse Kernels processes that request, at which point the response is returned to the client.
The detailed lifecycle of a write request can be found here:
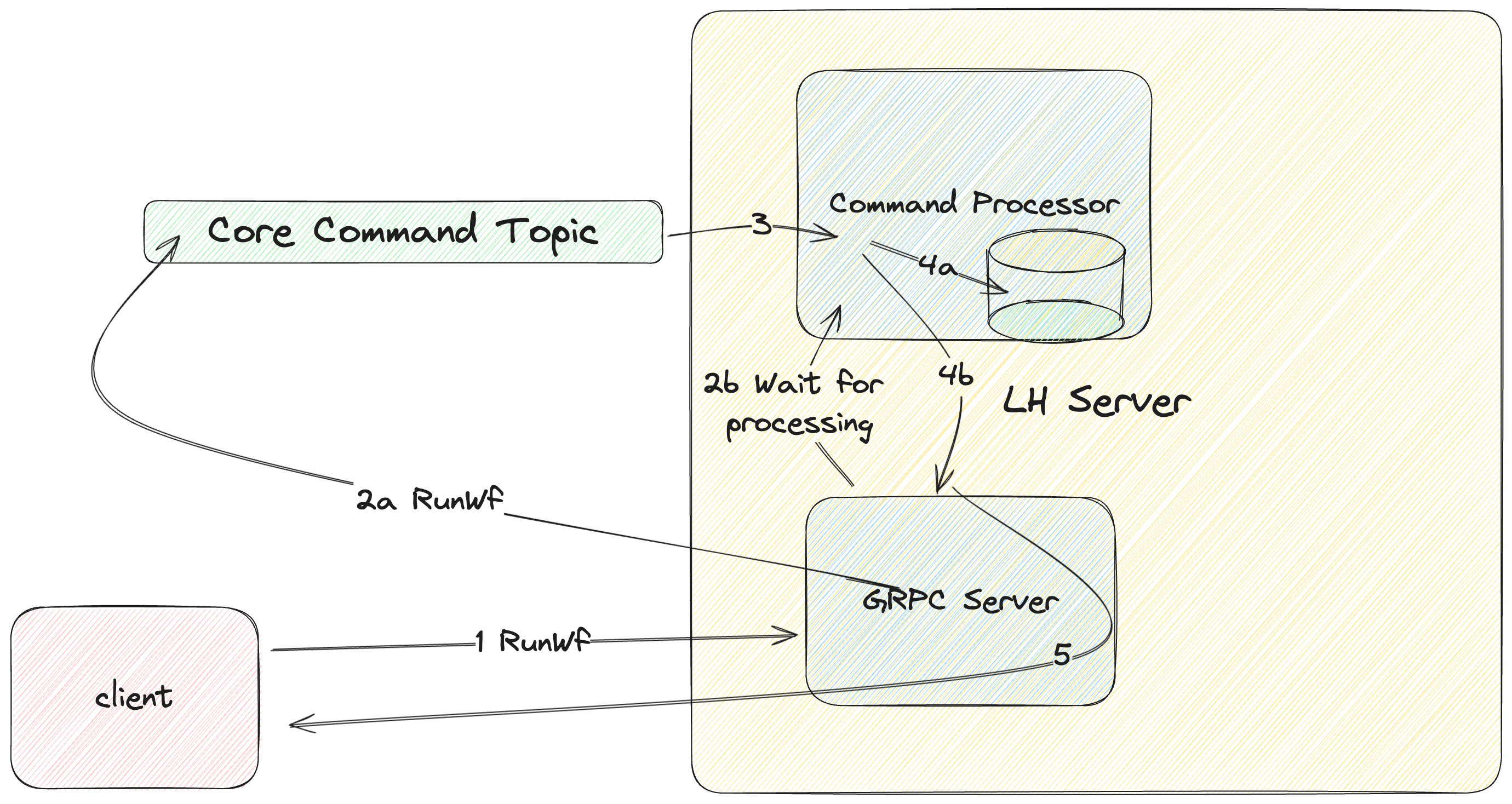
- Client sends request (eg. Create Workflow Specification) to LittleHorse Kernel.
- LittleHorse Kernel records the request (along with a Request Guid) to the core command Kafka Topic (
2a). LittleHorse Kernel contacts the designated Command Processor and asks to wait for the response for the Request Guid (2b). - The Command Processor processes the Command after reading it from the Core Command Topic.
- The Command Processor updates the state (eg. create the
WfRunObject) in the RocksDB State Store (4a). The Command Processor notifies the original calling LittleHorse Kernel of the results of the processing (4b). - The LittleHorse Kernel sends the results back to the client.
Because the data is stored in RocksDB on the same disk as where the processing happens, we can achieve extremely high throughput. The latency of a request is normally under 40ms, depending on your LittleHorse Kernel configuration and sizing.